In der Welt der Webanalyse sind Serverseitiges Tracking und Clientseitiges Tracking zwei verschiedene Ansätze, um Benutzerinteraktionen und -aktivitäten auf einer Website oder in einer Anwendung zu erfassen. Beide Methoden haben ihre eigenen Vor- und Nachteile, je nach Anwendungsfall und den Datenschutzanforderungen.
Serverseitiges Tracking bezieht sich auf die Erfassung von Daten direkt auf dem Webserver, auf dem eine Website oder Anwendung gehostet wird. Es erfasst Informationen über Benutzeraktivitäten, indem es HTTP-Protokolle analysiert, die vom Server generiert werden. Die Hauptvorteile von serverseitigem Tracking sind eine höhere Genauigkeit und geringere Abhängigkeit von Benutzer-Browsern, da es unabhängig von Browser-Einschränkungen arbeitet. Allerdings kann serverseitiges Tracking in der Regel weniger detaillierte Informationen über Benutzeraktivitäten und -interaktionen bereitstellen, da es nur auf die vom Server generierten Informationen zugreifen kann.
Mehr Infos: https://support.google.com/tagmanager/answer/13387731
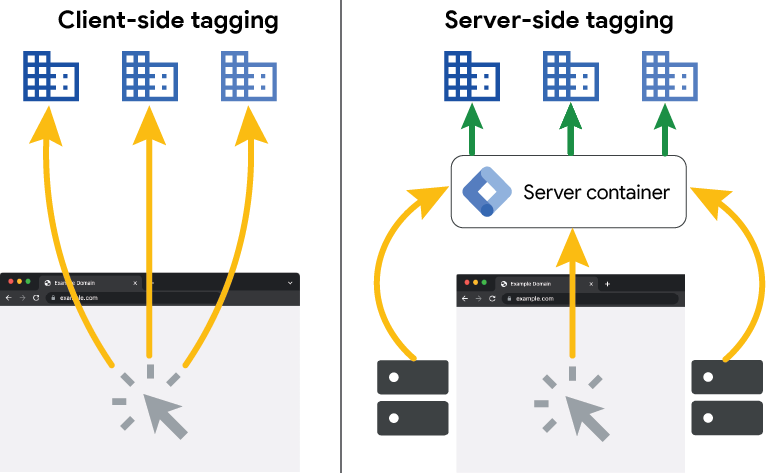
Clientseitiges Tracking hingegen erfasst Daten direkt vom Benutzergerät (z.B. Webbrowser) über JavaScript-Code, der in die Webseite eingebettet ist. Dies ermöglicht eine detailliertere Erfassung von Benutzeraktivitäten und -interaktionen, einschließlich Klicks, Seitenscrolls, Mausbewegungen und vieles mehr. Da clientseitiges Tracking von Browsern und Geräten abhängig ist, kann es jedoch von Ad-Blockern, Datenschutzeinstellungen oder Browser-Inkompatibilitäten beeinflusst werden, was zu ungenauen oder unvollständigen Daten führen kann.

Anna ist eine erfahrene Webanalyse-Spezialistin und Expertin in der Verwendung von Webanalyse-Tools wie Google Analytics, Adobe Analytics und Piwik, um Kunden dabei zu helfen, wertvolle Einblicke in ihre Website-Besucher zu gewinnen. Mit ihrem tiefen Verständnis für die Analyse von Daten und der Identifizierung von Mustern hilft Anna ihren Kunden, ihre Online-Präsenz zu verbessern und ihr Geschäft auszubauen.